gemclus.data.celeux_one¶
- gemclus.data.celeux_one(n=300, p=20, mu=1.7, random_state=None) Tuple[ndarray, ndarray][source]¶
Draws \(n\) samples from a Gaussian mixture with 3 isotropic components of respective means 1, 0 and 1 over 5 dimensions scaled by \(\mu\). The data is concatenated with \(p\) additional noisy excessive random variables that are independent of the true clusters. This dataset is taken by Celeux et al., section 3.1.
- Parameters:
- n: int, default=300
The number of samples to draw from the gaussian mixture models.
- p: int, default=20
The number of excessive noisy variables to concatenate to the dataset.
- mu: float, default=1.7
Controls how the means of the components are close to each other by scaling.
- random_state: int, RandomState instance or None, default=None
Determines random number generation for dataset creation. Pass an int for reproducible output across multiple runs.
- Returns:
- X: ndarray of shape (n, 5+p)
The samples of the dataset in an array of shape n_samples x n_features
- y: ndarray of shape (n,)
The component of the GMM from which each sample was drawn.
References
- Dataset - Celeux, G., Martin-Magniette, M. L., Maugis-Rabusseau, C., & Raftery, A. E. (2014). Comparing model
selection and regularization approaches to variable selection in model-based clustering. Journal de la Societe francaise de statistique, 155(2), 57-71.
Examples using gemclus.data.celeux_one¶
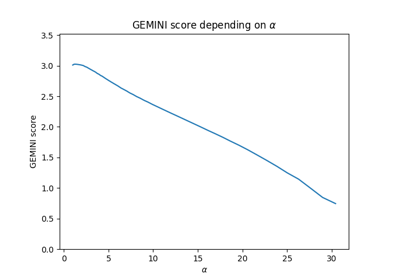
Feature selection using the Sparse MMD OvO (Logistic regression)
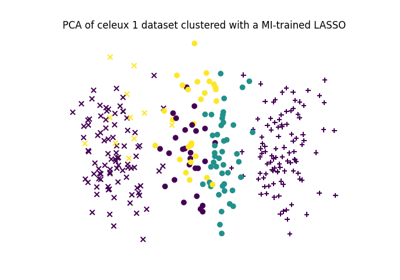
Feature selection using the Sparse Linear MI (Logistic regression)
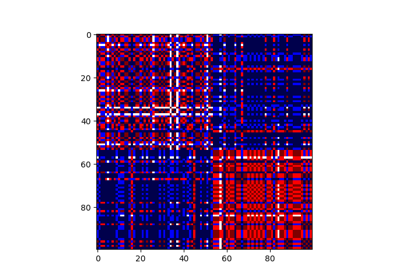
Consensus clustering with linking constraints on sample pairs